Varnishstat est un outil qui permet de voir les statistiques du cache Varnish en temps réel. C’est un outil très pratique pour s’assurer que Varnish fonctionne correctement. On peut y retrouver par exemple le hit ratio (rapport entre HIT et MISS), le nombre d’objets en cache, le nombre de threads Varnish, les requêtes en attente… Autant de valeurs qui permettront d’avoir une idée sur les performances de Varnish et sur les limites système qu’il peut rencontrer.
Description de varnishstat
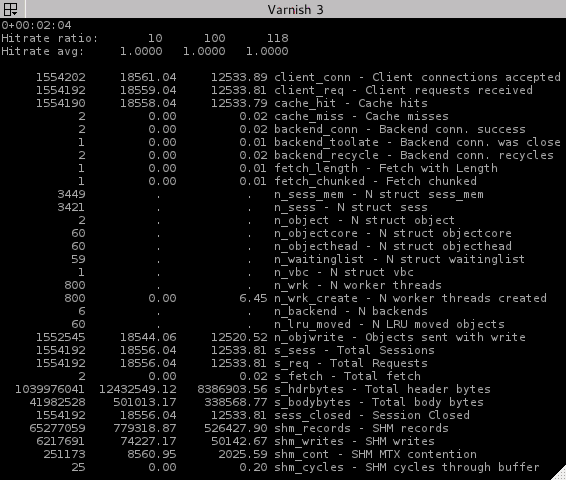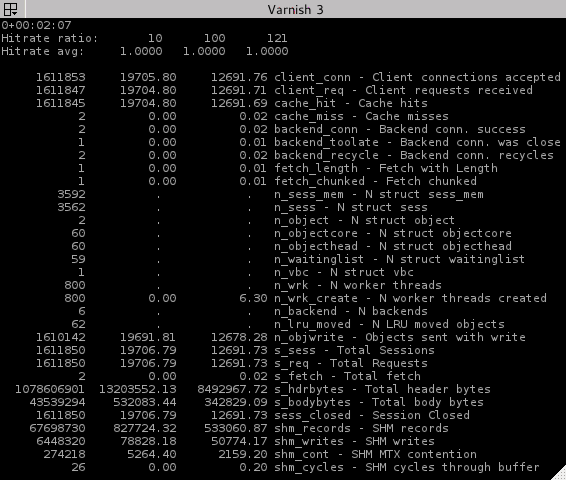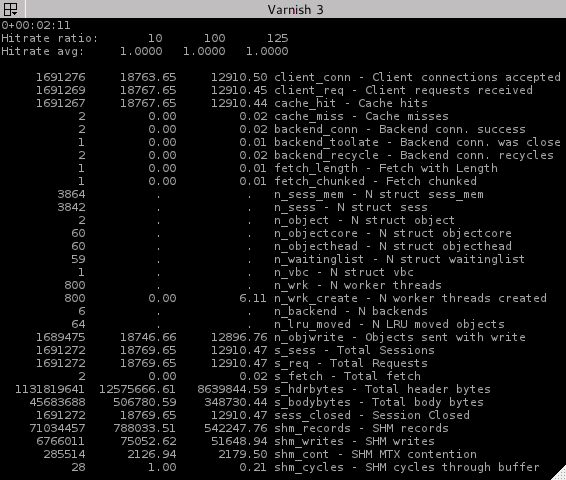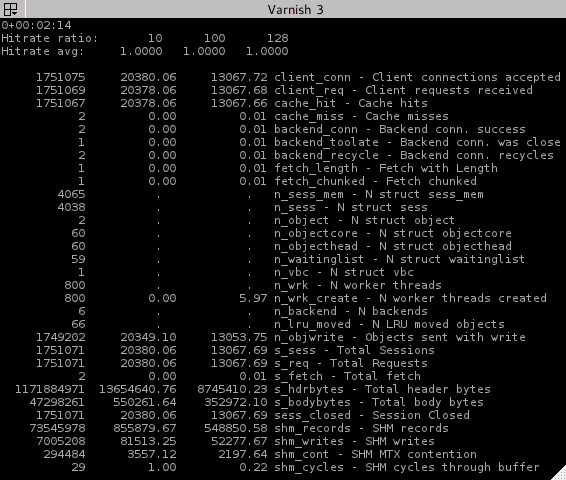
Sur cet exemple, un varnishstat, en haut à gauche, on observe :
- L’uptime du process Varnish. Seulement 2 minutes et quelques secondes sur cet exemple.
- Hitrate ratio et Hitrate avg : ces deux lignes vont ensembles. Hitrate ratio est la durée en secondes pour laquelle la valeur moyenne de Hitrate avg a été calculée. Les 3 colonnes de Hitrate ratio prendront progressivement pour valeur maximum 10, 100, 1000 secondes. Hitrate avg est donc la moyenne des hits sur cette durée (à multiplier par 100 pour une valeur en pourcentage). Évidemment, plus la valeur est proche de 1 (de 100% de hits donc), plus votre cache est efficace. Sur cet exemple on a donc un hitrate ratio de 100% sur les 10, 100 dernières secondes (bon, en trichant puisque j’ignore tous les cookies et que je force le TTL de toutes les pages de mon backend : c’était pour l’exemple).
On a ensuite un tableau de 4 colonnes avec :
- La valeur (un compteur) depuis le démarrage du process varnishd (remise à 0 au redémarrage de varnishd).
- La valeur instantanée (en secondes) depuis le dernier update de varnishstat.
- La moyenne (en secondes) depuis le démarrage de varnishd.
- Le nom de la valeur et sa description.
Si varnishstat est lancé avec l’option -1 : (varnishstat affiche les valeurs et rend la main)
- Le nom de la valeur.
- La valeur (un compteur).
- La moyenne depuis le lancement de varnishd.
- La description de la valeur.
Les valeurs à surveiller
Les connexions
client_conn 198596 9027.09 Client connections accepted
client_drop 0 0.00 Connection dropped, no sess/wrk
client_req 198596 9027.09 Client requests received
Les connexions client_conn et les requêtes client_req s’incrémentent. Quand client_req est incrémenté, la requête est complète et Varnish va y répondre. Dans cet exemple, on a par exemple 198596 connexions depuis le lancement de varnishd soit au moment du varnishstat -1 9027 connexions par secondes.
Performance du cache
cache_hit 198595 9027.05 Cache hits
cache_hitpass 0 0.00 Cache hits for pass
cache_miss 1 0.05 Cache misses
Ces indicateurs vous donnent une idée de l’efficacité de Varnish. Plus il y a de hits, mieux c’est. Si votre hit ratio est bas, il faut regarder quels sont les objets que Varnish n’a pas caché et pourquoi (via varnishlog). Il faudra adapter au mieux votre configuration VCL pour espérer augmenter votre ratio. Comme dans l’exemple précédent, on a ici 198595 hits depuis le démarrage de varnishd ce qui représente au moment du varnishstat -1 9027 hits par secondes.
Performance du backend
backend_conn 1 0.05 Backend conn. success
backend_unhealthy 0 0.00 Backend conn. not attempted
backend_busy 0 0.00 Backend conn. too many
backend_fail 0 0.00 Backend conn. failures
backend_reuse 0 0.00 Backend conn. reuses
backend_toolate 0 0.00 Backend conn. was closed
backend_recycle 1 0.05 Backend conn. recycles
backend_retry 0 0.00 Backend conn. retry
On a dans cet exemple les connexions TCP à votre backend et l’état de ces connexions. Par exemple, la première ligne backend_conn représente le nombre de connexions TCP réussies sur le backend (une seule ici vu mon TTL élevé et la durée du test). Si votre backend fait du keep-alive, Varnish va utiliser un pool de connexion. backend_recycle est incrémenté quand une connexion keep-alive rejoint le pool et backend.reuses le sera quand une connexion keep-alive est réutilisée.
Performance de varnishd
n_wrk 800 . N worker threads
n_wrk_create 800 13.33 N worker threads created
n_wrk_failed 0 0.00 N worker threads not created
n_wrk_max 0 0.00 N worker threads limited
n_wrk_lqueue 0 0.00 work request queue length
n_wrk_queued 0 0.00 N queued work requests
n_wrk_drop 0 0.00 N dropped work requests
On a ici une idée de l’état de santé de varnishd. n_wrk est le nombre de threads en cours d’utilisation alors que n_wrk_create est le nombre total de threads créés depuis le démarrage de varnishd. n_wrk_queued est le nombre de requêtes en file d’attente le temps qu’un thread se libère.
Les valeurs qui suivent doivent être à 0 :
- n_wrk_failed : nombre de threads qui n’ont pas pu être créés. Cela ne doit jamais arriver. Si c’est le cas, vous avez atteint les limites de votre serveur ou votre tuning est trop généreux !
- n_wrk_max : c’est le nombre de fois où varnishd a eu besoin de créer un nouveau thread sans y parvenir. A voir la valeur de thread_pool_max. Si cela intervient juste après le démarrage de varnishd, voir la variable thread_pool_add_delay.
- n_wrk_drop : nombre de requêtes que varnishd n’a pu traiter en raison de la file d’attente qui est pleine. Cela ne doit évidement jamais arriver. Cela peut venir de votre Varnish qui n’est plus suffisant pour absorber le trafic ou de la file d’attente, trop p>etite (voir alors thread_pool_max).
Toutes ces valeurs doivent vous aider à régler au mieux votre thread pool. Je reprends l’exemple de la documentation Varnish : si vous avez thread_pool_min à 5 et que varnishstat vous donne une utilisation en moyenne de 50 à 120 threads, il faudra certainement augmenter thread_pool_min à 50 (en partant du principe que vous avez 2 threads pool soit un total de 100 threads disponibles à tout moment). Dans le cas contraire, vous verrez au niveau de varnishstat que varnishd va créer des threads régulièrement. Les threads en attente ne sont pas couteux d’un point de vue ressources système contrairement à la création de threads.
Les objets en cache
n_lru_nuked 0 . N LRU nuked objects
n_lru_moved 75 . N LRU moved objects
n_lru_nuked doit être à 0 : c’est le nombre d’objets purgés par manque de place. Si vous n’êtes pas à 0, votre cache est trop petit. n_lru_moved représente le nombre de fois où la liste des objets a été mise à jour.
Divers
n_gzip 0 0.00 Gzip operations
n_gunzip 8 0.13 Gunzip operations
Une idée du nombre d’opérations de compression/décompression des objets. Il faudra penser à normaliser l’entête Accept-Encoding afin d’éviter de décompresser un objet pour rien (j’y reviendrai dans un prochain article).
backend_req 2 0.00 Backend requests made
n_expired 0 . N expired objects
esi_errors 0 0.00 ESI parse errors (unlock)
esi_warnings 0 0.00 ESI parse warnings (unlock)
Dans l’ordre, nous avons le nombre total de requêtes sur votre backend, le nombre d’objets expirés (par exemple un TTL arrivé à 0), les erreurs ESI (si vous l’avez activé).
Les options de varnishstat
| option | détail |
|---|---|
| -1 | comme vu plus haut dans l’article, cela permet d’afficher les statistiques une fois et de quitter la commande. |
| -f | permet de filtrer la sortie de varnishstat sur la liste de valeurs passées en paramètre. Les valeurs sont séparées par des virgules. Si on préfixe la liste avec ^, les variables sont exclues. |
| -l | liste des valeurs affichées par varnishstat. Ces valeurs peuvent être passées en paramètre de varnishstat via l’option -f. |
Exemple :
varnishstat -1 -f client_conn,client_req,cache_hit,cache_miss,backend_fail,n_wrk,\n_wrk_failed,n_wrk_max,n_wrk_drop,n_lru_nuked
client_conn 2090985 13234.08 Client connections accepted
client_req 2090983 13234.07 Client requests received
cache_hit 2090981 13234.06 Cache hits
cache_miss 2 0.01 Cache misses
backend_fail 0 0.00 Backend conn. failures
n_wrk 800 . N worker threads
n_wrk_failed 0 0.00 N worker threads not created
n_wrk_max 0 0.00 N worker threads limited
n_wrk_drop 0 0.00 N dropped work requests
n_lru_nuked 0 . N LRU nuked objects
| option | détail |
|---|---|
| secondes | le delais en secondes du raffraichissement de varnishstat. |
| -x | permet une sortie comme avec l’option -1 mais en XML. |
Exemple : varnishstat -x -f cache_hit,cache_miss
<?xml version="1.0"?>
<varnishstat timestamp="2011-09-16T23:06:05">
<stat>
<name>cache_hit</name>
<value>2090981</value>
<flag>a</flag>
<description>Cache hits</description>
</stat>
<stat>
<name>cache_miss</name>
<value>2</value>
<flag>a</flag>
<description>Cache misses</description>
</stat>
</varnishstat>
A retenir
Utilisez varnishstat pour vérifier le bon fonctionnement de votre cache et pour détecter les variables à optimiser pour augmenter les performances de Varnish. Si vous rencontrez un problème, enregistrez la sortie de varnishstat -1 avant d’arrêter ou de relancer varnishd afin d’éviter de perdre vos statistiques (pour une éventuelle investigation).