Puppet est un outil de gestion de configuration. Il permet de mettre à jour de façon automatisée et selon un scénario prédéfini un ensemble de serveurs clients. L’idée est de décrire l’état désiré du serveur et Puppet se chargera de réaliser les actions nécessaires pour y parvenir.
Puppet est écrit en Ruby, sous licence Apache. Basé sur une architecture client/serveur, il est multi-plateforme.
Grace à l’utilisation de Puppet, on va pouvoir :
- Configurer de façon homogène un ensemble de serveurs.
- Contrôler et corriger tout écart de configuration.
- Faire du déploiement rapide de serveurs.
- Augmenter le niveau de sécurité : déploiement rapide de patchs, mise à jour de paquets, alerte si une configuration est modifiée…
D’autres outils sont disponibles pour de la gestion de configuration : Chef, CfEngine, bcfg2.
Historique
A l’origine, Puppet a été créé par un utilisateur averti de CfEngine, déçu de la solution et de la façon dont était géré le projet. Plus tard, un utilisateur de Puppet lancera le projet Chef, déçu à son tour par la programmation non déterministe de Puppet. Deux articles sur le sujet :
Comment ça marche ?
Langage déclaratif Puppet : L’idée est de définir un certain nombre de ressources et leurs relations afin d’amener le serveur dans l’état désiré. Si l’état du serveur diffère de l’état désiré, Puppet réalisera les actions nécessaires pour y remédier. Pour cela, on dispose d’un langage déclaratif propre à Puppet dont le modèle est implémenté comme un graphe orienté acyclique : il faut définir les relations et les dépendances entre les ressources pour obtenir l’ordre d’exécution recherché (contrairement à un langage procédural ou l’ordre d’exécution serait implicite).
Exemple : si mon programme a besoin d’un fichier de configuration File dans le répertoire Directory, je vais devoir clairement écrire :
- mon programme a besoin d’un fichier de configuration nommé File.
- mon fichier de configuration File doit être stocké dans le répertoire Directory qui doit donc être présent.
Couche d’abstraction des ressources : Puppet utilise une couche d’abstraction des ressources (RAL) : le client Puppet saura automatiquement faire une installation d’un paquet indépendamment du système d’exploitation.
Par exemple, en langage Puppet, j’écris :
package { 'htop':
ensure => present,
}
Mon client Debian va faire :
apt-get install htop
Mon client Redhat va faire :
yum install htop
Inventaire système avec Facter : Facter est un système d’inventaire système pour Puppet (également écrit en Ruby) qui remonte au serveur un certain nombre d’informations au format “clé => valeur” disponible en tant que variable dans les scénarios Puppet.
On peut ainsi récupérer par exemple : le hostname, le domaine, l’ip… Il est possible de créer facilement ses propres “clés => valeurs”.
Pour résumer, voici un schéma de Puppet Labs qui décrit le fonctionnement de Puppet :
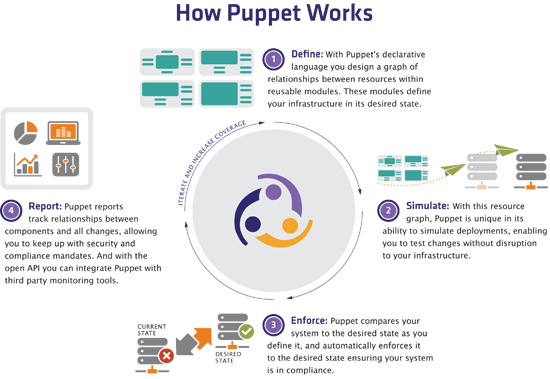
Vocabulaire Puppet
Voici un peu de vocabulaire propre à Puppet :
- “Puppetmaster” est le serveur Puppet qui héberge la configuration et les manifests, modules…
- Un client est un “node”.
- Le scénario à jouer est un “manifest”.
- Dans ce “manifest”, on a un ensemble de “ressources”. Il y a des ressources pour gérer les paquets, les fichiers, les users…
- On peut regrouper ces “ressources” dans des classes (qui supportent l’héritage) qu’il sera ensuite possible d’associer à des “nodes”.
- On peut faire des “modules”, un ensemble de “manifests”, de “classes”, de fichiers et “templates”, librairies Ruby.
- On peut utiliser des “templates” pour par exemple générer des fichiers. Les “templates” sont en ERB.
- Le “catalogue” est l’ensemble des classes compilées par le serveur. Il est téléchargé en local par le client Puppet (ce qui permettra au client de continuer à fonctionner si la connexion au serveur n’est plus possible).
A savoir
- Les échanges client/serveur se font en XML-RPC via une connexion HTTPS. Un échange de clé SSL se fait à la première connexion du client sur le serveur. La clé du client doit ensuite être signée (de façon manuelle ou automatique) pour que la communication soit autorisée.
- Le client Puppet se connectera au serveur toutes les 30 minutes (configuration par défaut) pour récupérer son catalogue. Il est possible également de déclencher depuis le Puppetmaster le lancement du Puppet client.
- Par défaut, Puppet est peu scalable. Il utilise le serveur web “webrick” qui aura bien du mal à répondre si vous avez beaucoup de clients. On peut bien entendu scaler Puppet en remplaçant, par exemple “webrick” par un Apache+Passenger. J’y reviendrai dans un article sur la scalabilité.
- La configuration des noeuds peut être exportée dans une base de donnée, dans un LDAP, dans le dashboard de Puppet Labs ou foreman, dans un programme externe du langage de votre choix qui fournira la définition du “node” en YAML.
- Des “dashboards” sont disponibles pour consulter l’état de vos serveurs, la base de donnée constituée par Facter, les rapports d’exécution de Puppet…
- On peut créer ses propres Facts, créer des librairies Ruby, ses propres “ressources”.
- Puppet sait gérer de multiples “environnements” : production, développement. Cela permet d’avoir certains clients connectés à la branche développement de votre Puppetmaster et de s’assurer du bon fonctionnement de vos modules avant de les activer pour la production.
- Une API REST permet par exemple de consulter l’inventaire facter…
- Puppet peut fonctionner en standalone sur un serveur.
- Puppet dispose d’une forte communauté. Des modules sont disponibles sur la forge Puppet : module Munin client/serveur, gestion APT, Apache…
Pour finir
Il n’y a pas de limite à l’utilisation d’un outil de gestion de configuration. On peut tout faire, tout gérer. On peut aussi et très facilement tout casser ! Un mauvais fichier de configuration distribué sur tous vos serveurs, un package retiré, un user supprimé…
Il faut donc être très rigoureux à l’installation et à la maintenance de cet outil. L’idée est de, par exemple, respecter les bonnes pratiques de Puppet Labs, versionner ses modules (Git, svn…), correctement dimensionner son Puppetmaster en fonction du nombre de clients, utiliser un environnement de développement pour développer ses scénarios et les tester avant de les basculer sur l’environnement de production…
Cela imposera certainement des changements dans la gestion que vous faites de vos serveurs. Là où aujourd’hui, vous intervenez directement sur le serveur (pour rétablir un service, rajouter des utilisateurs…), dès que ce service, ce serveur sera “Puppétisé”, il faudra passer par Puppet pour faire les mises à jour afin d’éviter, dans le cas contraire, l’écrasement des modifications locales !
Les schémas de cet article sont tirés de cette page :
Lien vers la documentation, le wiki et autres :