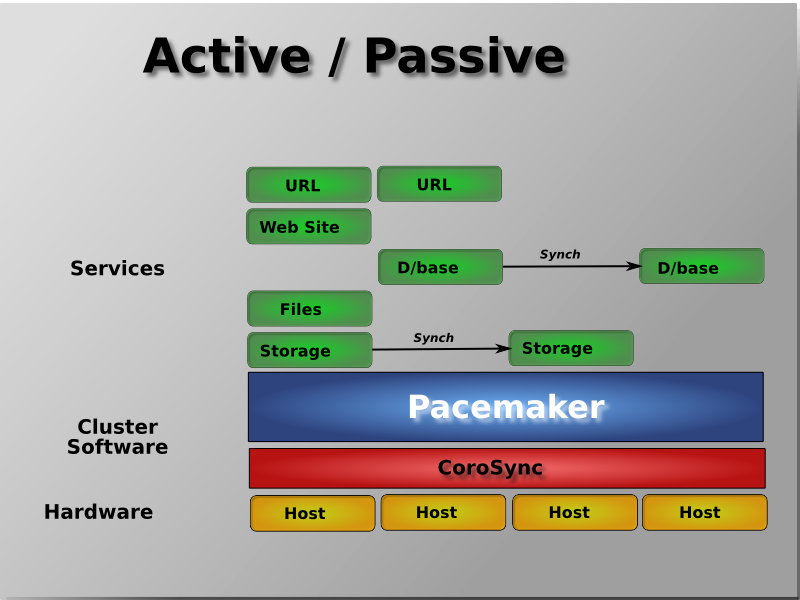
Suite de l’article des clusters avec pacemaker : nous allons voir ici comment mettre en place un cluster de deux noeuds, en actif / passif avec deux ressources : une VIP et Apache. Le besoin est le suivant : apporter de la haute disponibilité au serveur http Apache. La VIP (adresse IP virtuelle) et Apache devront fonctionner sur le même noeud, basculer sur l’autre noeud en cas de panne du noeud actif ou si une ressource est en erreur au-delà de la valeur définie.
Rappels et définitions
- Un cluster actif/passif fonctionne de cette façon : les ressources sont démarrées et supervisées par Pacemaker sur un seul noeud : le noeud actif (appelé également master ou maître). Si ce noeud rencontre une panne, les ressources sont basculées sur l’autre noeud, le noeud passif (ou le slave, l’esclave), qui devient alors le noeud actif. Quand l’autre noeud est de nouveau fonctionnel, deux possibilités :
- Rien ne change : le cluster reste dans cette configuration. Le noeud réparé devient le noeud passif du cluster. Cela évite une nouvelle bascule et une nouvelle interruption du service. On parle alors de “manual failback” ou “d’auto_failback à off”.
- On retourne dans l’état précédent : il y a une nouvelle bascule. Le noeud réparé redevient le noeud actif du cluster. Il y a une nouvelle interruption du service. Cela correspond à activer “l’auto_failback”.
- Votre service, Apache ici, est démarré et supervisé par Pacemaker. Il est donc inutile (voir problématique dans certains cas) de démarrer le service au boot de votre serveur. C’est uniquement à Pacemaker de gérer maintenant ce service. Pour désactiver le démarrage du service sur une Debian :
- Sur une debian Squeeze si vous utilisez les dépendances entre les scripts d’init :
insserv -r -v apache2
- Sur une version inférieure à la 6.0 (Squeeze) :
update-rc.d -f apache2 remove
- Le service, Apache ici, doit être installé et configuré de façon identique sur les deux noeuds. Il ne faudra jamais oublier de reporter toute modification de la configuration sur l’ensemble des noeuds sous peine d’avoir, le jour d’une bascule, un service potentiellement dégradé.
- Pour les problématiques liées au stonith et au quorum que j’ai détaillé ici, nous allons ignorer le quorum et désactiver le stonith. C’est la base de toutes les configurations que je vais vous présenter.
- Au sujet des exemples de configuration qui vont suivre : tout doit se faire sur une seule ligne. Vous pouvez couper les lignes longues via “" suivi d’un retour à la ligne (comme dans les exemples) ou tout saisir sur une ligne. Par exemple plus bas, la syntaxe primitive commence avec “primitive” et se termine après la définition du “timeout”, le tout, sur une ligne.
La configuration de base
Vous avez donc configuré Corosync, Apache sur vos deux noeuds. Corosync est démarré et la commande crm_mon -1 renvoie quelque chose de semblable à :
root@ha-test1:~# crm_mon -1
============
Last updated: Mon Oct 24 23:50:20 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
0 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
On a donc 2 noeuds en ligne, pas de ressources configurées. On va commencer par configurer stonith et le quorum de ce cluster comme expliqué dans le paragraphe précédent. On injecte la configuration suivante via crm configure :
crm(live)configure# property no-quorum-policy="ignore"
crm(live)configure# property stonith-enabled="false"
crm(live)configure# commit
On vérifie la configuration via la commande show du mode configure :
crm(live)configure# show
node ha-test1
node ha-test2
property $id="cib-bootstrap-options" \
dc-version="1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
no-quorum-policy="ignore" \
stonith-enabled="false"
crm configure en image :

Le cluster est prêt pour recevoir la définition des ressources…
La VIP
La VIP est l’adresse de service de votre cluster. C’est l’adresse virtuelle à utiliser pour accéder à votre service en haute disponibilité. Cette adresse IP sera ajoutée comme adresse secondaire sur l’interface réseau de votre choix. Pour configurer ce service, toujours dans crm configure, injectez la configuration suivante puis validez via la commande commit :
primitive VIP1 ocf:heartbeat:IPaddr2 \
params ip="192.168.0.10" broadcast="192.168.0.255" nic="eth1" cidr_netmask="24" iflabel="VIP1" \
op monitor interval="30s" timeout="20s"
Le détail de cette syntaxe :
- On commence avec primitive qui sert à déclarer une ressource. VIP1 est le nom de votre ressource. ocf:heartbeat:IPaddr2 est le script utilisé pour gérer cette ressource. Dans cette syntaxe on retrouve ocf pour le type de script : c’est un script qui sait gérer le start/stop d’une ressource comme avec un script lsb, mais il permet en plus et c’est très utile, la supervision de la ressource via monitor (ou encore la promotion d’une ressource dans le cadre d’un cluster actif/actif…). Suit ensuite heartbeat le “fournisseur” du script puis le nom du script IPaddr2. Pour information, il existe également un script IPaddr. Je vous encourage à utiliser IPaddr2 qui permet d’utiliser des interfaces cachées ou encore, par exemple, de cloner une VIP (article à venir).
- Toujours sur la même ligne, on a une liste de paramètres avec params qui définit l’adresse IP de cette VIP. Déclarez votre VIP avec son adresse, son broadcast, son masque et l’interface réseau sur laquelle sera rajoutée cette VIP. Le paramètre iflabel permet de donner un label à votre VIP. Sans ce label, la VIP n’est pas visible avec la commande “ifconfig” mais seulement avec “ip addr show”.
- Pour finir, op monitor défini un moniteur pour cette ressource : toutes les 30 secondes, Pacemaker va appeler le script ocf avec comme paramètre monitor. Avant le timeout de 20 secondes, on devra avoir un code retour à 0 pour que Pacemaker considère la ressource comme fonctionnelle. Dans le cas contraire, il arrêtera/relancera la ressource ou effectuera une bascule (idem si la fonction monitor n’a pas répondu avant le timeout).
Voici la sortie de crm_mon -1 :
============
Last updated: Mon Oct 24 23:51:33 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test1
Une ressource configurée dans mon cluster qui fonctionne sur le noeud ha-test1. Je contrôle via ifconfig :
eth1:VIP1 Link encap:Ethernet HWaddr 00:01:02:03:04:05
inet addr:192.168.0.10 Bcast:192.168.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Apache
Nous avons vu précédemment comment rajouter une adresse IP virtuelle pour accéder au service en haute disponibilité. Reste maintenant le service en question : Apache. De la même manière que nous avons défini la VIP, nous allons rajouter Apache :
primitive APACHE ocf:heartbeat:apache \
params configfile="/etc/apache2/apache2.conf" \
op monitor interval="30s" timeout="20s" \
op start interval="0" timeout="40s" \
op stop interval="0" timeout="60s"
Je ne reviens pas sur le détail complet de cette configuration. Comme pour la VIP, on définit la primitive APACHE avec pour paramètre le fichier de configuration d’apache de la Debian. Pour information, pour connaître la liste complète des paramètres d’une primitive, utilisez la commande crm ra list ocf:heartbeat:apache. Vous obtenez la liste des timeout par défaut, des paramètres et de leurs valeurs par défaut, les paramètres obligatoires et facultatifs… Par rapport à la configuration de la VIP, nous avons :
- op start qui va définir le timeout par défaut pour la fonction start du script ocf.
- op stop pour la fonction stop du script ocf.
Vérifions l’état du cluster suite à l’ajout de cette nouvelle ressource :
============
Last updated: Mon Oct 24 23:52:42 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
2 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test1
APACHE (ocf::heartbeat:apache): Started ha-test2
Ajustements
Quelques ajustements s’imposent : il faut que l’ensemble des ressources fonctionnent ensemble, sur le même noeud et en cas d’échec sur l’une des ressources (au 3ème échec), il faudra basculer sur l’autre noeud. Il y a donc deux cas de bascule :
- Le noeud actif à une panne : les ressources sont basculées sur le noeud passif.
- Une ressource échoue au delà de la valeur configurée, les ressources basculent. Si un problème est rencontré au moment du démarrage d’une ressource, la bascule sur l’autre noeud est immédiate.
La configuration se passe toujours via crm configure :
crm(live)configure# group APACHE-HA VIP1 APACHE meta migration-threshold="3"
crm(live)configure# commit
On utilise la syntaxe group pour grouper nos ressources VIP1 et APACHE sous le nom de groupe APACHE-HA. Au troisième échec d’une des ressource de ce groupe, il y aura une bascule du cluster. Dans le cas contraire, la ressource en échec est relancée.
Attention à l’ordre de vos ressources (primitives) dans le groupe ! Quand vous groupez vos ressources, vous indiquez que vous souhaitez les faire fonctionner ensemble, ce qui se traduit dans notre exemple par :
- APACHE doit fonctionner sur le même noeud que la VIP1.
- APACHE a alors une dépendance à la ressource qui le précède : la VIP VIP1.
- Si la VIP1 bascule, APACHE bascule. C’est le fonctionnement recherché. Mais si la VIP1 ne fonctionne plus, elle sera arrêtée puis relancée impliquant l’arrêt relance d’APACHE qui dépend de cette VIP ! Idem si vous coupez volontairement cette ressource, APACHE ser>a coupé.
- On a le schéma de démarrage/relance des ressources suivant : START VIP -> START APACHE et si problème sur la VIP : STOP APACHE -> STOP VIP -> START VIP -> START APACHE. Si la ressource APACHE est relancée, pas d’impact : APACHE n’a pas de dépendance dans cette dé>claration du groupe.
- C’est peu contraignant dans notre exemple à une seule VIP puisque APACHE écoute sur celle-ci : si la VIP ne fonctionne pas, inutile qu’Apache fonctionne. Mais dès qu’il y aura plusieurs VIPs, ce fonctionnement peut être problématique. En effet, dans le cas où nou>s aurions le groupe suivant : group APACHE-HA VIP1 VIP2 APACHE, si on souhaite changer/couper/faire une intervention sur la VIP1, l’arrêt de celle-ci engendrera l’arrêt des ressources au-dessus : VIP2 et APACHE. Pour éviter ce comportement, il existe une autre solu>tion à base de colocation/order (que nous verrons dans un prochain article). C’est un détail du group à garder en tête !
On vérifie que le groupe est bien en place et que les ressources sont maintenant sur le même noeud :
============
Last updated: Mon Oct 24 23:53:04 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
Resource Group: APACHE-HA
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test2
APACHE (ocf::heartbeat:apache): Started ha-test2
Pour désactiver l’auto_failback, je donne un poids par défaut à mon noeud actif avec default-resource-stickiness. Le positionnement des ressources sur un noeud se fait en fonction du poids calculé pour chacun d’entre eux. Vous pouvez par exemple privilégier un noeud en lui donnant un poids plus important qu’un autre. Ainsi, les ressources auront pour “préférence” ce noeud. Dans cet exemple, il n’y a pas de préférence sur un noeud, juste un poids de +10 attribué à l’actif. Via crm configure :
property default-resource-stickiness="10"
commit
C’est prêt. Il reste maintenant à valider par des tests, des tests, des tests…
Les tests
Arrêt d’un noeud
Le premier test que je réalise est l’arrêt du noeud actif. Rien de tel qu’un arrêt électrique pour vérifier le comportement du cluster. Avant la coupure, tout va bien comme le confirme la commande crm_mon -1 :
============
Last updated: Tue Oct 25 22:29:29 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
Resource Group: APACHE-HA
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test2
APACHE (ocf::heartbeat:apache): Started ha-test2
Mes deux noeuds sont “online” et mes ressources fonctionnent sur ha-test2. Je coupe ha-test2 électriquement :
============
Last updated: Wed Oct 26 22:58:59 2011
Stack: openais
Current DC: ha-test1 - partition WITHOUT quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ ha-test1 ]
OFFLINE: [ ha-test2 ]
Resource Group: APACHE-HA
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test1
APACHE (ocf::heartbeat:apache): Started ha-test1
On remarquera au passage le partition WITHOUT quorum. Si le quorum n’était pas ignoré, le cluster n’aurait pas basculé ! Quand le serveur est rallumé, il réintègre le cluster automatiquement. Comme l’auto_failback est désactivé, il n’y a pas de bascule, on reste dans cet état :
============
Last updated: Wed Oct 26 23:00:20 2011
Stack: openais
Current DC: ha-test1 - partition with quorum
Version: 1.0.9-74392a28b7f31d7ddc86689598bd23114f58978b
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ ha-test1 ha-test2 ]
Resource Group: APACHE-HA
VIP1 (ocf::heartbeat:IPaddr2): Started ha-test1
APACHE (ocf::heartbeat:apache): Started ha-test1
Arrêt d’une ressource
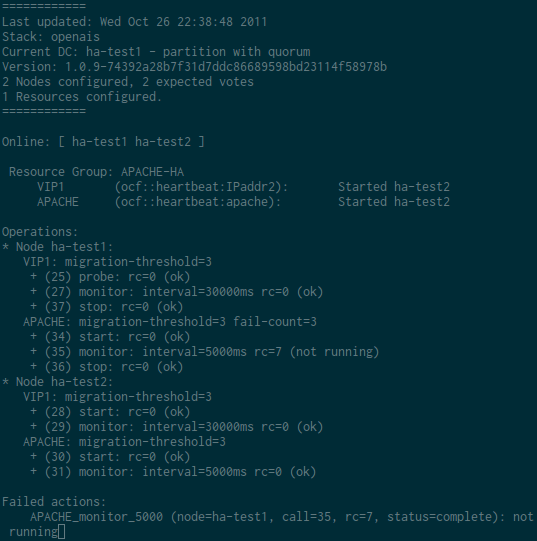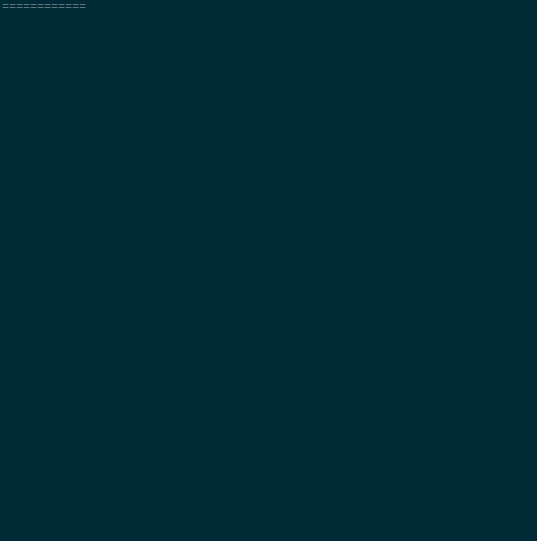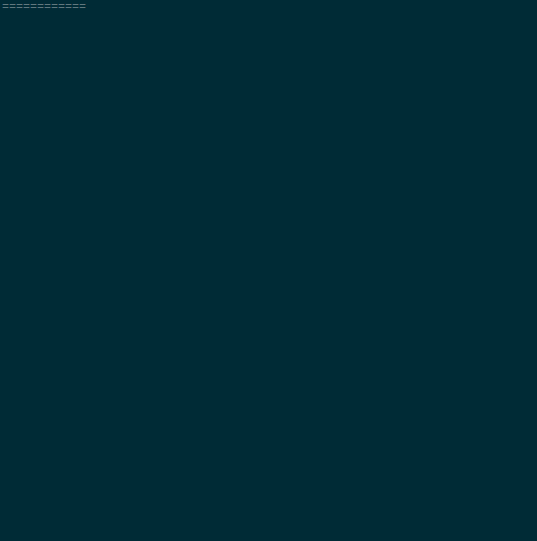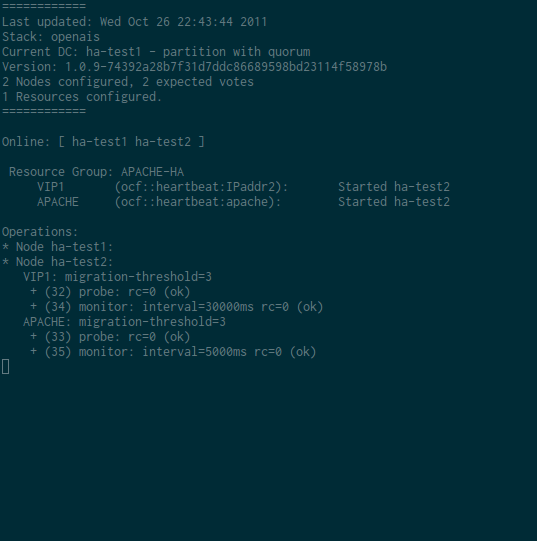
Dans l’exemple qui suit, j’arrête apache. Le fonctionnement demandé est de relancer la ressource 2 fois et de basculer sur l’autre noeud au 3ème échec. Pour suivre le comportement de Pacemaker, j’ai fait la capture suivante. Pour ce test, j’ai volontairement réduit l’intervalle du moniteur d’Apache à 5 secondes. J’envoie ensuite 3 killall apache2 sur le noeud actif pour vérifier que le cluster fonctionne correctement. On pourra observer par exemple la ligne APACHE: migration-threshold=3 fail-count=3 avec la valeur de fail-count qui sera incrémenté à chaque relance de la ressource par Pacemaker.
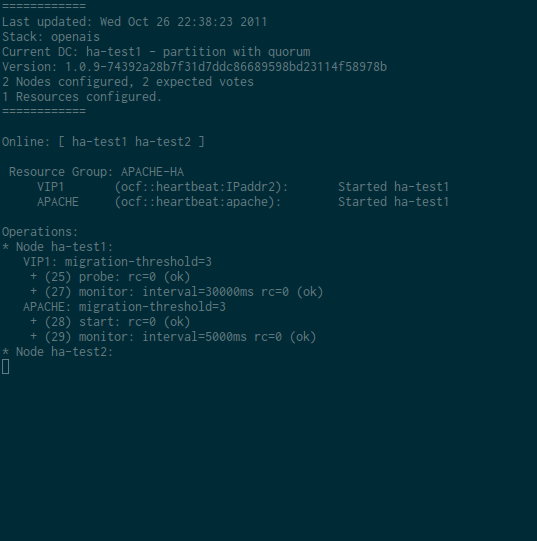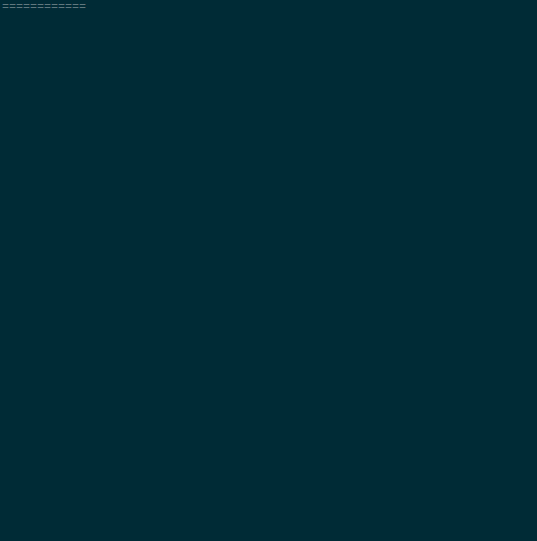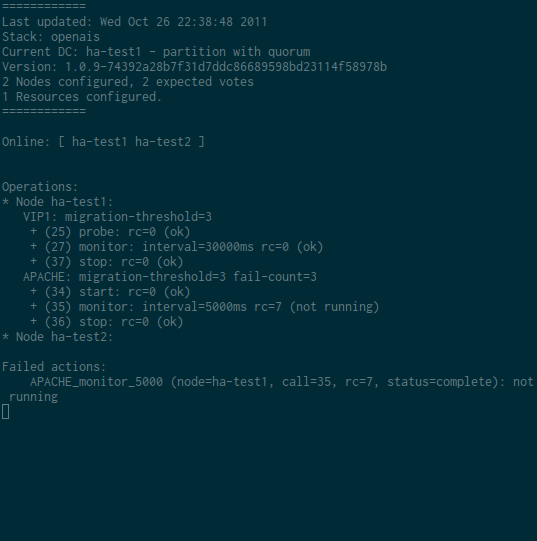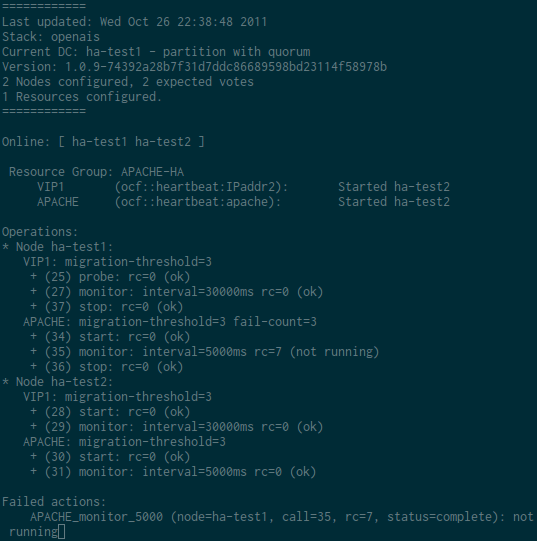
Résultat d’un crm resource cleanup APACHE-HA :
Mettre un noeud en standby
Il peut être utile, pour de la maintenance par exemple, de mettre un noeud en standby. Sur l’exemple qui suit, je fais un crm node standby ha-test2, le noeud actif de mon cluster. Dans ce cas, le cluster bascule sur l’autre noeud.
Résultat d’un crm node standby ha-test2 :
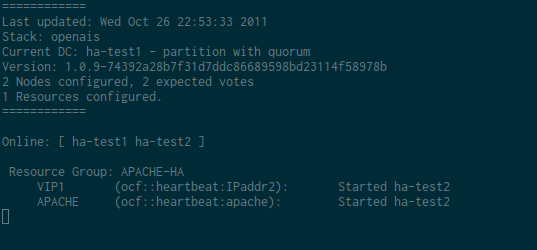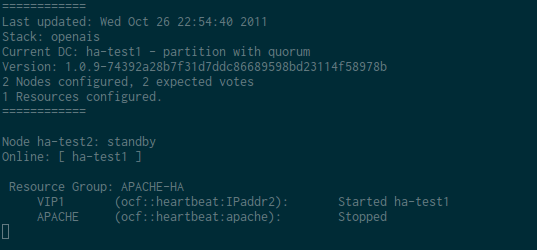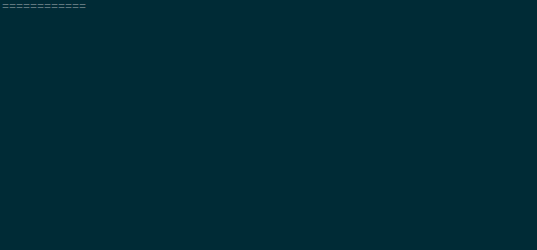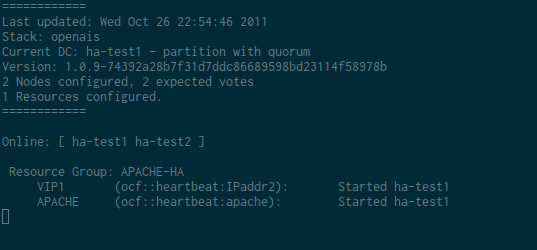
Conclusion / Liens
Nous avons vu le cas d’un cluster simple actif/passif. Il est possible de monter des clusters plus compliqués à plus de 2 noeuds, en mode actif/actif, avec des conditions sur les ressources (ma ressource doit fonctionner, par exemple, que les jours ouvrés). Idem pour les fonctions de crm. Il existe d’autres possibilités pour migrer les ressources, gérer le fail-count et le cluster en lui-même. A suivre…
Pour la documentation sur Pacemaker :